Testing webcrawler with selenium
01 Nov 2019사용 목적
웹에 있는 크래시 리포팅정보에서 앱의 크래시율을 매일 아침 메일로 받아보기 위함
크래시 리포팅을 해주는곳에서 정보를 얻어올 수 있는 API가 없어서 웹에서 정보를 가져오기로 함
찾아본 결과 selenium 모듈과 크롬 웹브라우저를 사용하는게 괜찮아 보여서 테스트 함
chrome 세팅
chrome 버전 확인하고

버전에 맞는 크롬 드라이버를 다운로드 해야 된다.
https://sites.google.com/a/chromium.org/chromedriver/downloads
다운받고 압축을 푼다음 chromedriver.exe 파일 위치를 기억해 놓는다.
테스트 코드
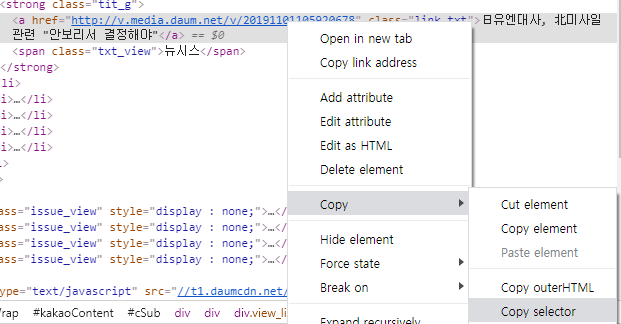
찾을 selector 값이 필요
from selenium import webdriver
import time
from bs4 import BeautifulSoup
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.action_chains import ActionChains
g_browser = None
g_wait = None
def login():
global g_browser
global g_wait
g_browser.get(
"https://logins.daum.net/accounts/signinform.do?url=https%3A%2F%2Fwww.daum.net%2F"
)
g_wait.until(EC.presence_of_all_elements_located)
# iframe에 id값이 존재하면 find로 접근하지 못해서 switch해줘야 한다, 이것때문에 계속 element를 찾지 못함
# iframe = g_browser.find_element_by_id("ptlogin_iframe")
# g_browser.switch_to.frame(iframe)
input_str = g_browser.find_element_by_id("id")
input_str.send_keys("아이디")
input_str = g_browser.find_element_by_id("inputPwd")
input_str.send_keys("비밀 번호")
time.sleep(3)
g_browser.find_element_by_xpath('//*[@id="loginBtn"]').click()
# ActionChain으로 원하는 곳으로 마우스를 이동할 수 있다.
# flowCanvas = .find_element_by_id('Some Canvas xPath')
# action = ActionChains(g_browser)
# action.move_to_element(flowCanvas)
# action.move_by_offset(500, 0).perform() -> flowCanvs로 이동후 right 500으로 이동
# 밑에 코드도 동작함, 클릭이 가능할때 처리
# WebDriverWait(g_browser, 20).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="loginBtn"]'))).click()
# 버튼에 엔터 처리해도 됨
# button = g_browser.find_element_by_id('login_button')
# button.send_keys(Keys.ENTER)
time.sleep(3)
g_browser.get("https://media.daum.net")
html = g_browser.page_source
soup = BeautifulSoup(html, "html.parser")
# 크롬 검사에서 selector값을 얻어올 수 있다
notices = soup.select("#cSub > div > div:nth-child(2) > div > ul > li.item_main > strong > a")
for n in notices:
print(n.text.strip())
time.sleep(5)
def main():
global g_browser
global g_wait
# chromedriver 경로
g_browser = webdriver.Chrome("C:\chromedriver")
g_browser.implicitly_wait(3)
g_wait = WebDriverWait(g_browser, 10) # wait for at most 10s
login()
main()
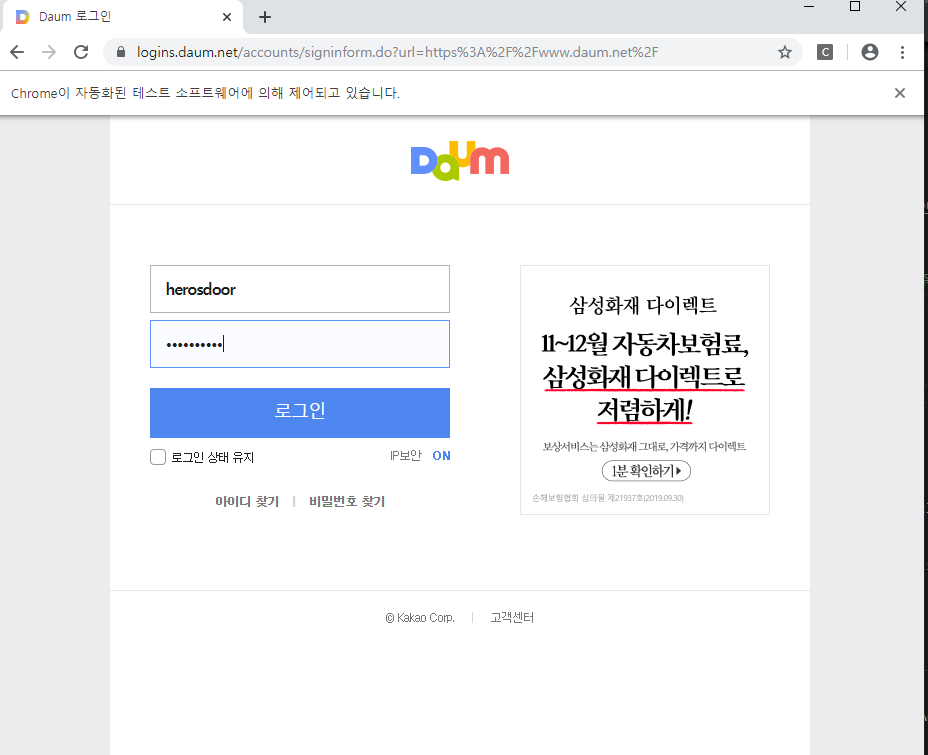
실행 결과
자동 실행후 아이디 비번 입력, 로그인까지 해준다.
찾은 기사의 메인 제목
